Our solution is to simply map the affordances back to the first frame without the human.
Extracting Affordances Without Extra Annotations
Robot-centric Affordances: While visual affordances have been studied extensively in computer vision, applying them to robotics needs smart tweaks. As we learn from large-scale human videos but apply to robots, we seek an agent-agnostic affordance to facilitate this transfer. Therefore, we define affordance as:
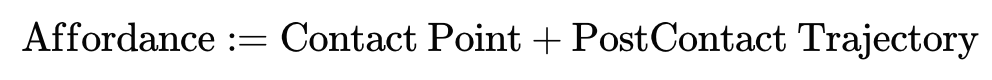
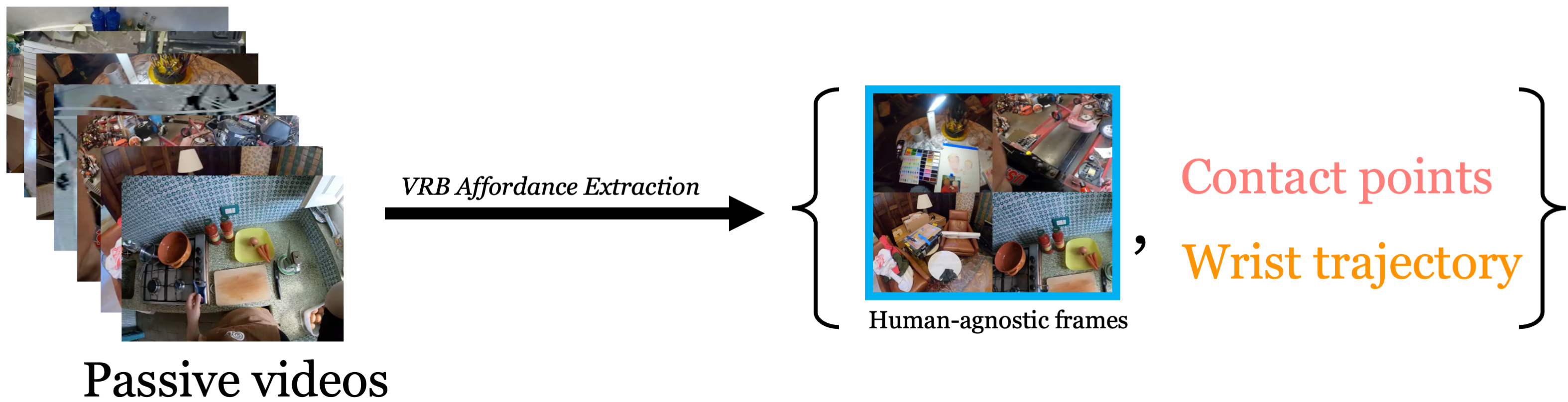
We extract affordances from large scale human video datasets such as Ego4D and Epic Kitchens. We use off the shelf hand-object interaction detectors to find the contact region and post contact wrist trajectory.
We first find the contact point using a hand object interaction detector, and the post contact trajectory by tracking the wrist. Once we have detected these frames, a major issue is that the the human is still in the scene , leading to a distribution shift.
We use available camera information to project both the contact points and the post-contact trajectory to the human-agnostic frame. This frame is used as input to our model.
Our Affordance Pipeline

Illustration of annotation pipeline : Find the frame with hand-object contact, track the wrist to obtain the post contact trajectory, map both to the first human entry frame for reference.
VRB: Model
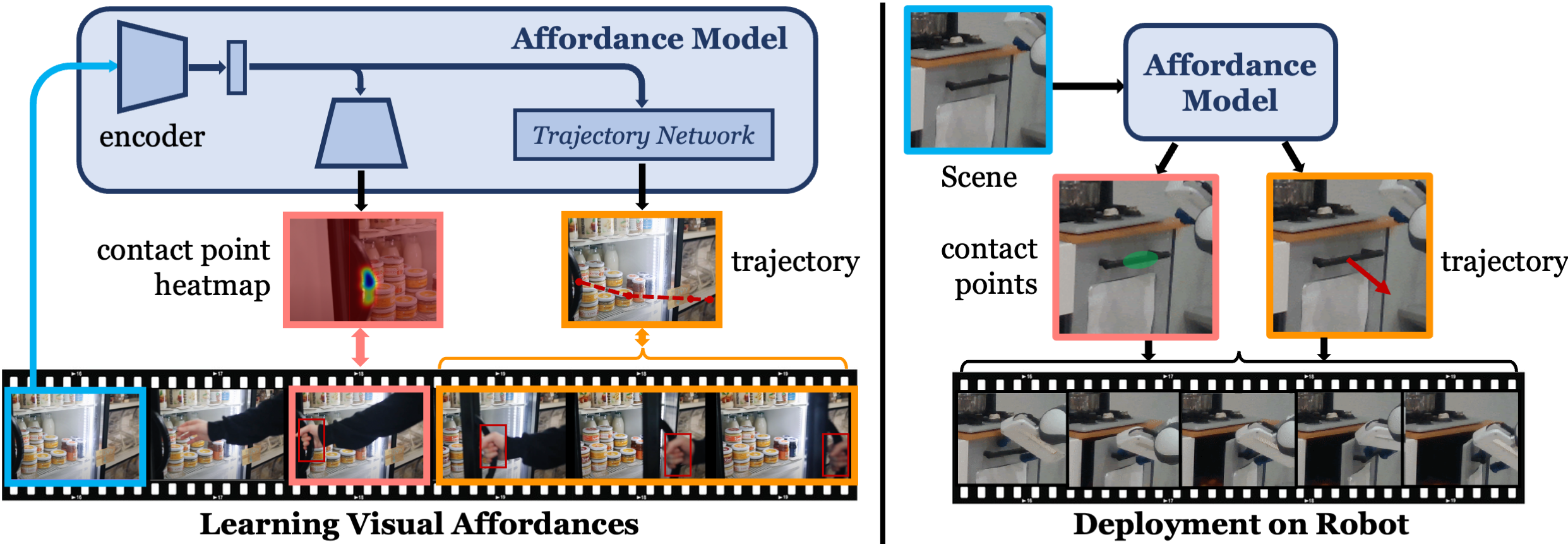
Our model takes a human-agnostic frame as input. The contact head outputs a contact heatmap (left) and the trajectory transformer predicts wrist waypoints (orange). This output can be directly used at inference time (with sparse 3D information, such as depth, and robot kinematics).
Applications to Robotics
We benchmark VRB on 10+ Tasks, 2 robot morphologies, 4 learning paradigms
Robot Learning Paradigms
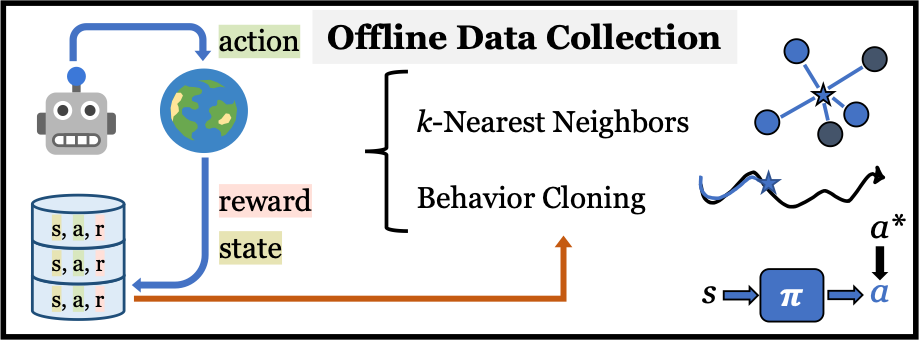

Robot Learning Paradigms (Top-Left) Affordance-model driven data collection for offline imitation. (Top-Right) Reward free exploration. (Bottom-Left) Goal-conditioned policy learning with our affordance model. (Bottom-Right) Using the affordance model outputs to reparameterize actions.
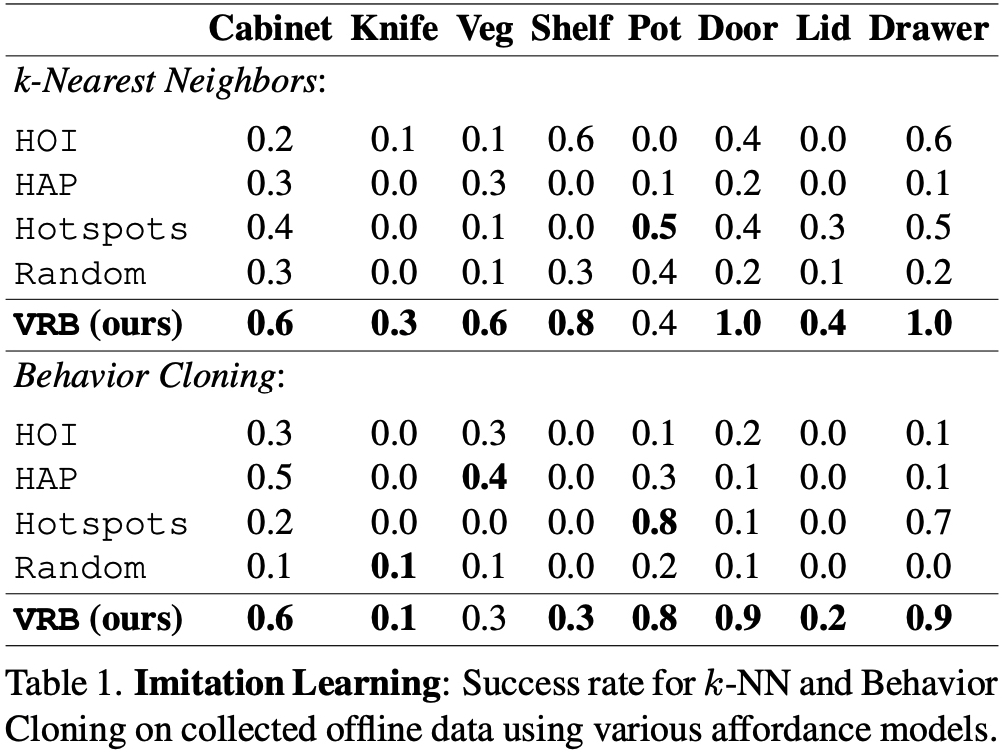
Affordance Model-based Data Collection
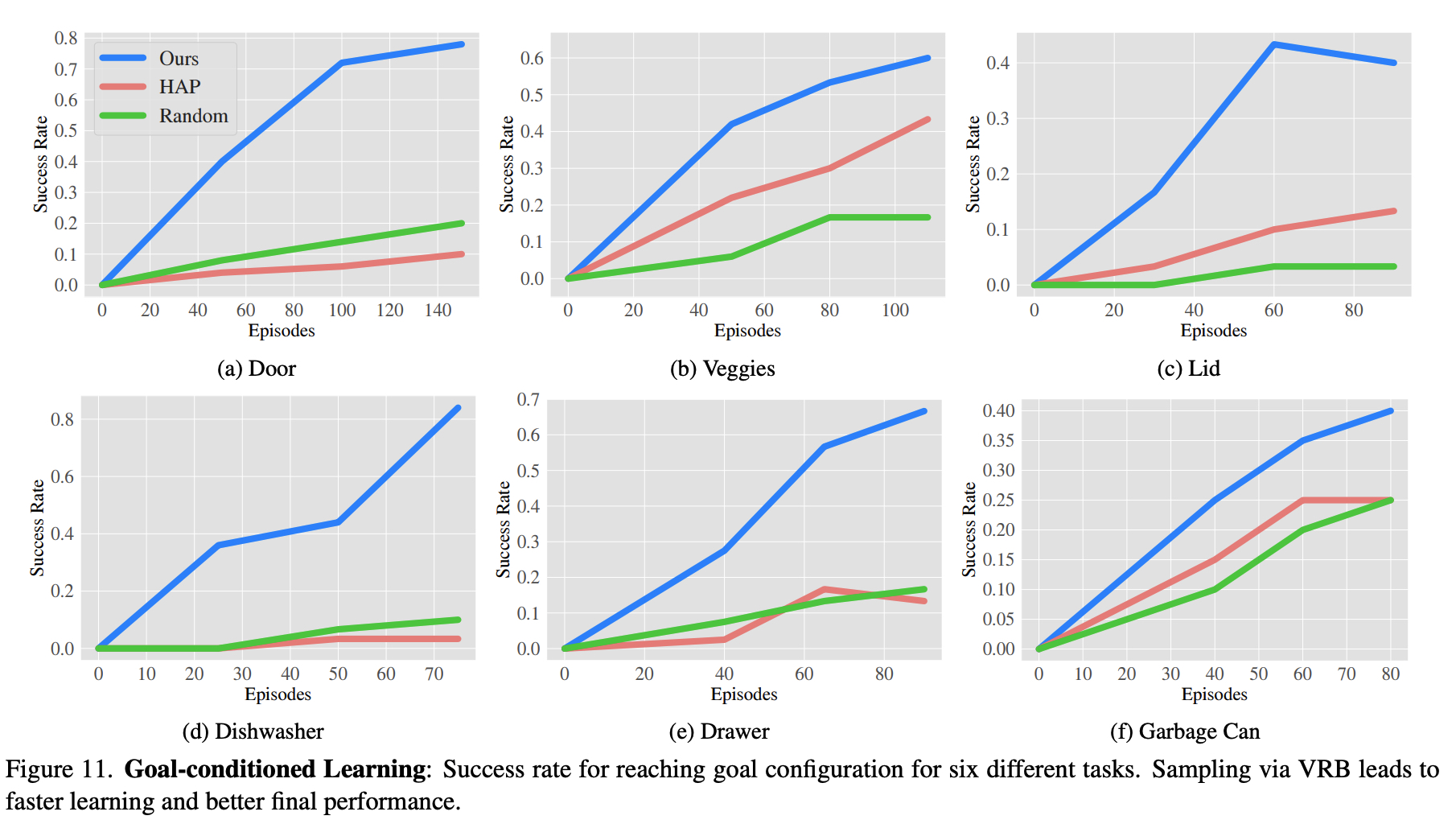
Goal-Conditioned Learning
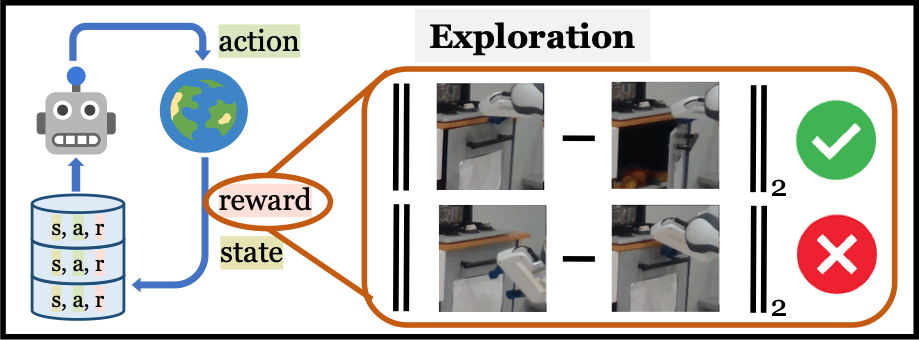
Reward-Free Exploration
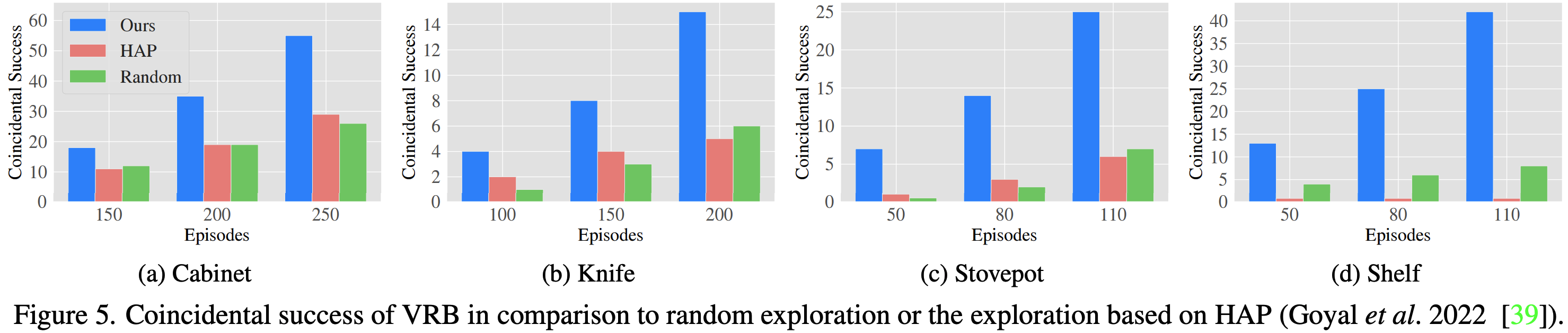
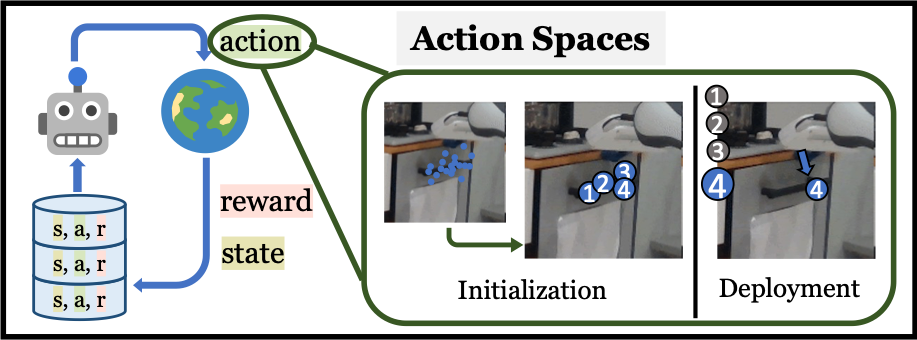
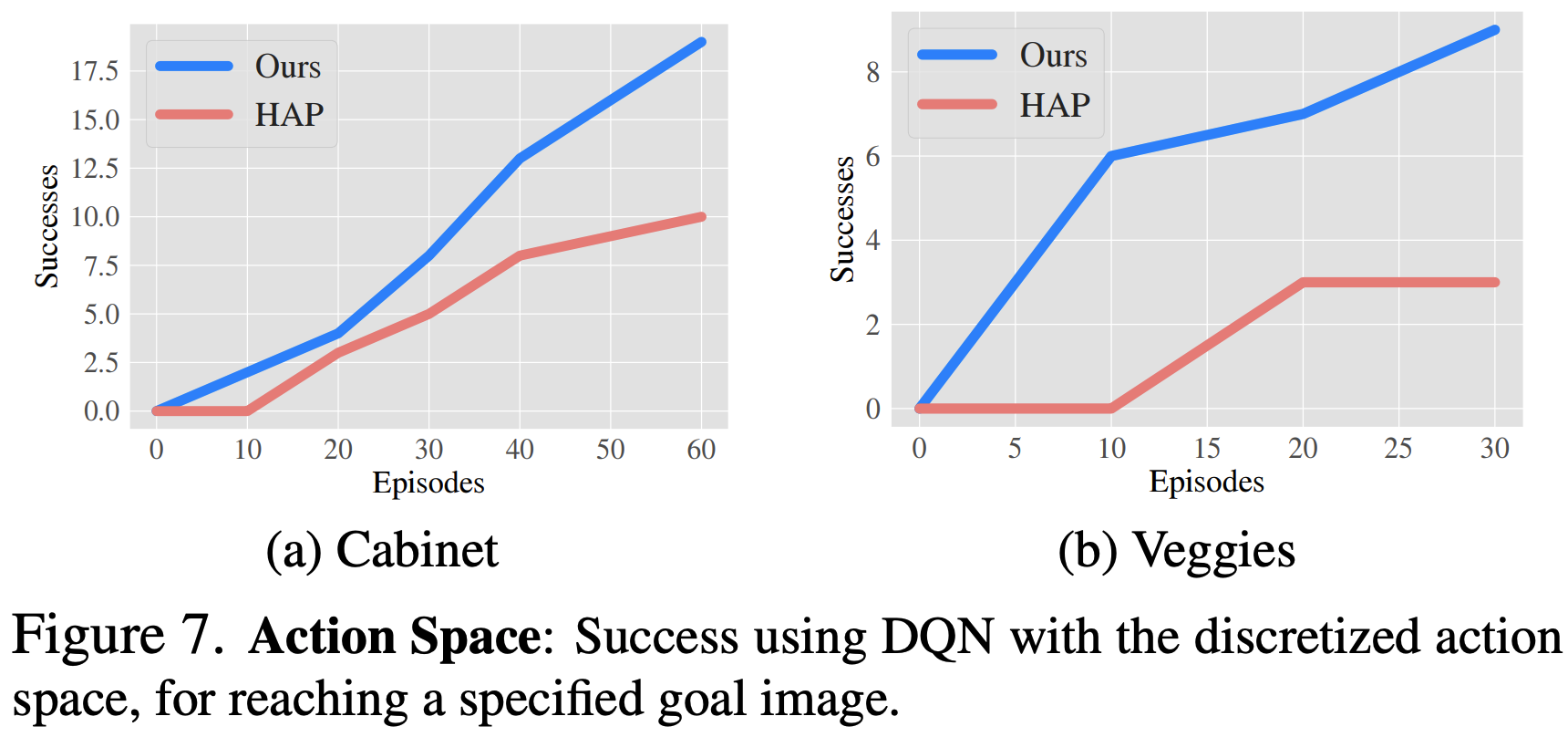
Visual Affordances as Action Spaces
Project Video
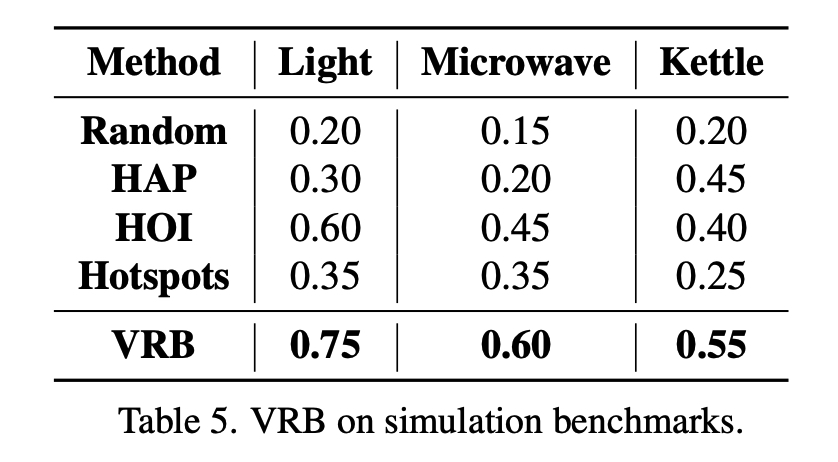
Simulation Benchmark

We have also tested VRB on a simulation benchmark, specifically, the Franka Kitchen benchmark from D4RL. Our method demonstrates superior performance compared to the baselines on three distinct tasks within the benchmark.
Handling Rare Objects
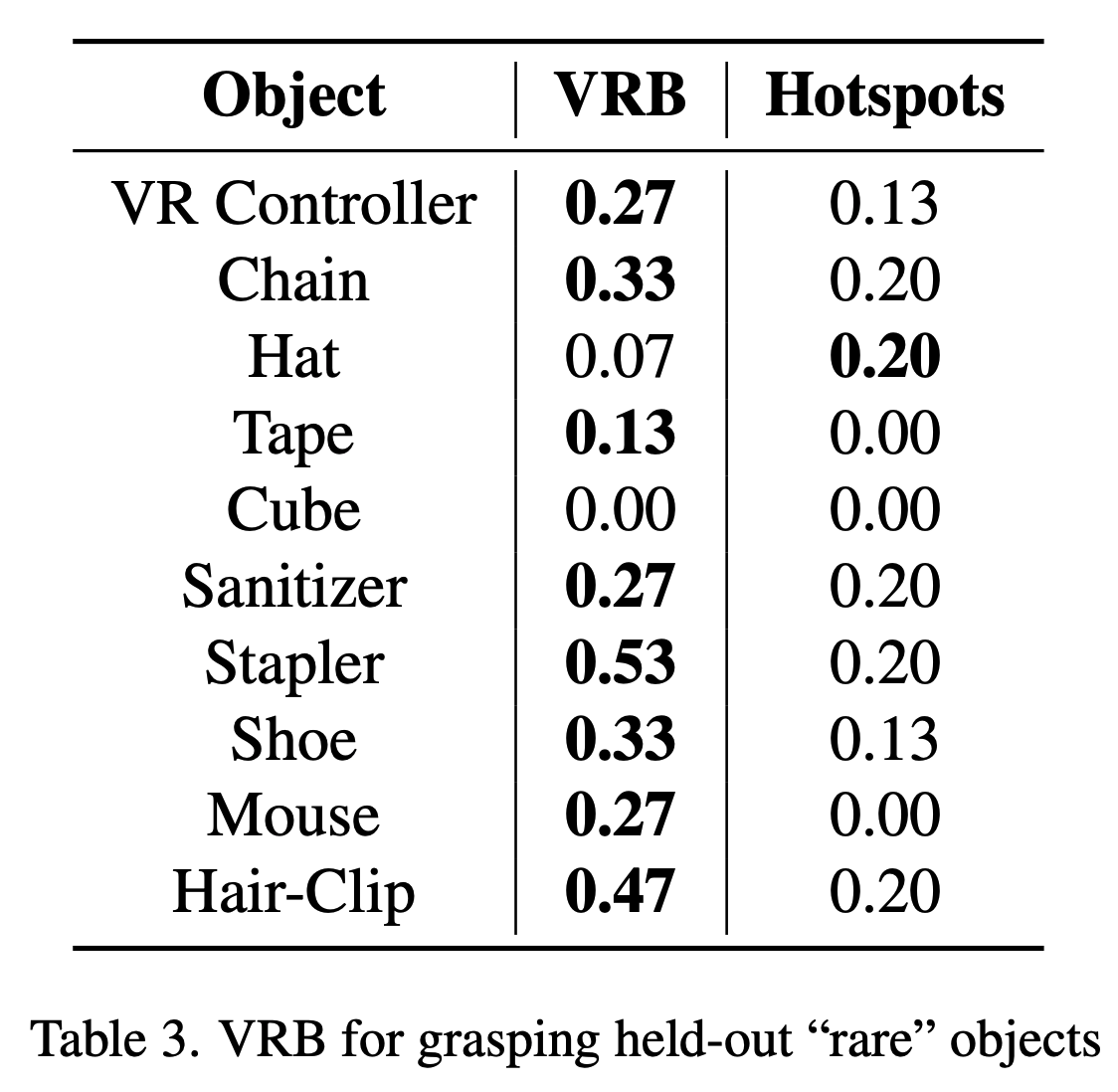
VRB demonstrates effective handling of rare objects, outperforming the Hotspots baseline in grasping various held-out items. This showcases VRB's adaptability to different tasks and environments.
BibTeX
@inproceedings{bahl2023affordances,
title={Affordances from Human Videos as a Versatile Representation for Robotics},
author={Bahl, Shikhar and Mendonca, Russell and Chen, Lili and Jain, Unnat and Pathak, Deepak},
journal={CVPR},
year={2023}
}Acknowledgements
We thank Shivam Duggal, Yufei Ye and Homanga Bharadhwaj for fruitful discussions and are grateful to Shagun Uppal, Ananye Agarwal, Murtaza Dalal and Jason Zhang for comments on early drafts of this paper. RM, LC, and DP are supported by NSF IIS-2024594, ONR MURI N00014-22-1-2773 and ONR N00014-22-1-2096.